Fecha: 13/04/2026
Estas notas cubren la definición de Ecuaciones Diferenciales Ordinarias (ODEs), su aplicación en modelado dinámico, la conversión de otros tipos de ecuaciones a ODEs, y cómo se utilizan para la estimación de parámetros a partir de datos observacionales, culminando con la introducción a las Neural ODEs (NODEs).
Ecuaciones diferenciales ordinarias (ODEs)¶
Las ODEs describen la evolución de un sistema en función de una única variable independiente, típicamente el tiempo .
Definición y Parámetros¶
Una ODE queda definida de la siguiente manera:
Variable de estado: representa el estado del sistema en el instante .
Dinámica: Está determinada por una función , conocida como campo vectorial, y un conjunto de parámetros del modelo .
Forma general:
donde .
Condición inicial: . Define el estado de partida del sistema (condición inicial) en el tiempo inicial .
Salvo casos muy particulares, las soluciones a ODEs no suelen admitir soluciones en forma cerrada. Por lo tanto, en la mayoria de los casos, vamos a recurrir a métodos numéricos para resolver dichas ecuaciones (ver Clase 4).
Ejemplos¶
El Modelo Dinámico: Lotka-Volterra (Depredador-Presa)
Este modelo describe la dinámica temporal del estado de un sistema compuesto por dos poblaciones: conejos () y lobos ().
Intuición de la dinámica:
Si los conejos están solos, se reproducen exponencialmente: .
Si los lobos están solos, mueren exponencialmente: .
Para modelar la interacción (los lobos se comen a los conejos), se agrega un término no lineal .
Las ecuaciones del modelo estan entonces dadas por
Componentes del sistema:
Vector de estado: . Depende del tiempo y está parametrizado por . Para cada conjunto de parámetros, las curvas temporales (trayectorias) serán diferentes. Suelen ser oscilatorias.
Condición inicial: e .
Vector de parámetros: . El sistema es no lineal por la presencia de términos de interacción bilineales .
: tasa de crecimiento de conejos.
: tasa de depredación.
: tasa de mortalidad de lobos.
: tasa de crecimiento de lobos por interacción.
Para un mismo estado inicial, distintos valores de producen trayectorias muy distintas, así que estimar es parte central del problema.
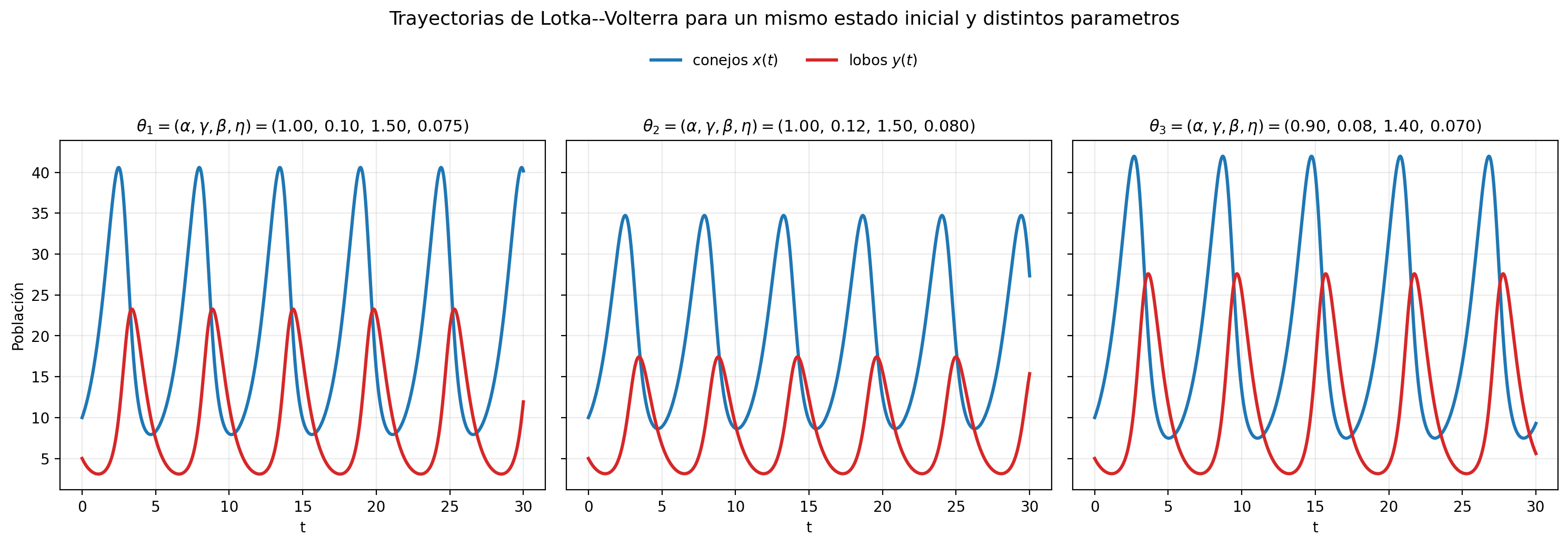
Trayectorias temporales de conejos (x(t)) y lobos (y(t)) para un mismo estado inicial y distintos valores de f.
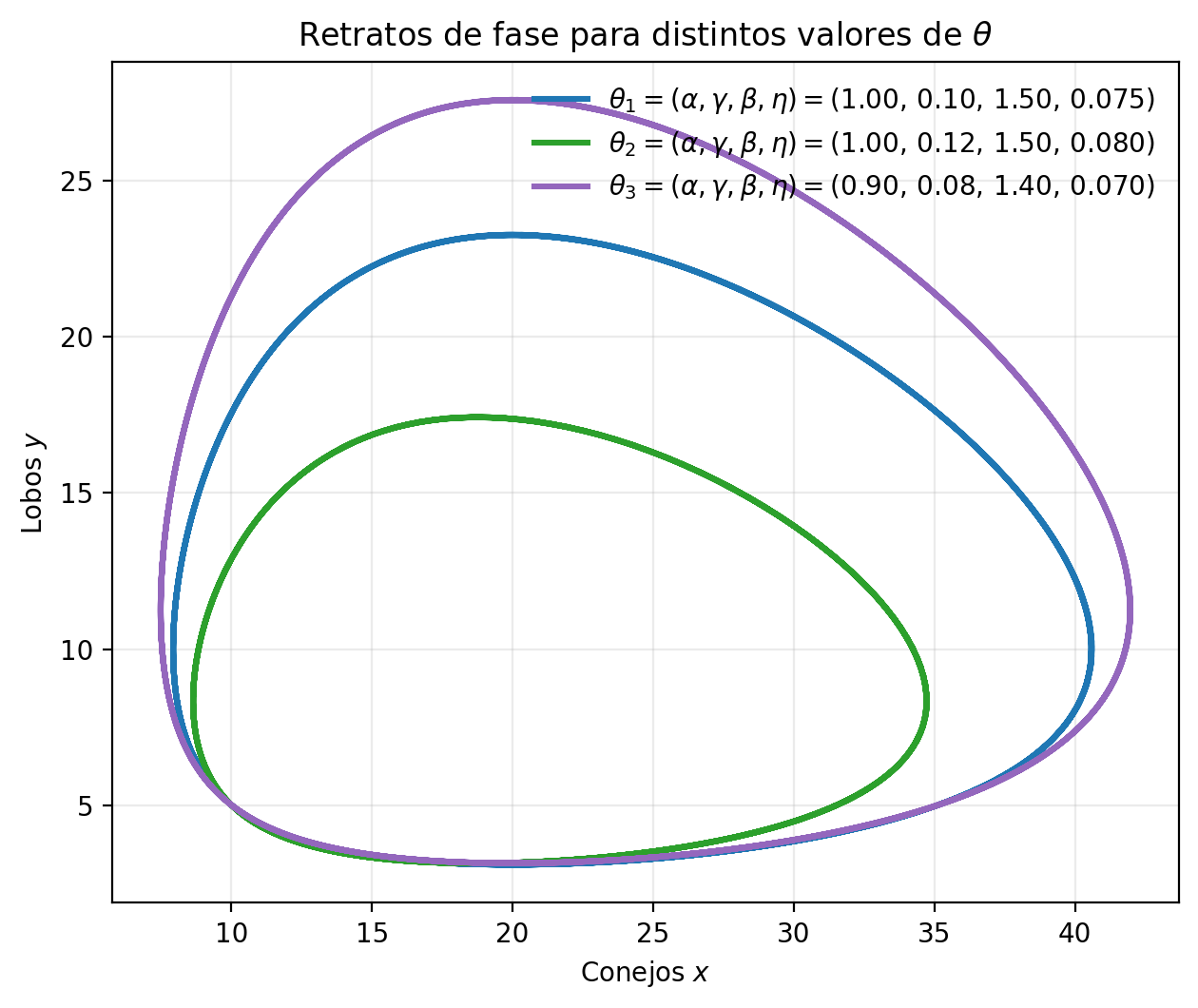
Retratos de fase del sistema de Lotka--Volterra para distintos valores de .
Inferencia estadística¶
En la realidad, si uno tuviera conocimiento absoluto de la dinámica, conocería la trayectoria perfecta. Sin embargo, nunca se observan estas trayectorias puras. En su lugar, se observan datos, usualmente en tiempos discretos, que se asemejan a la trayectoria subyacente, pero posiblemente contaminados con ruido aleatorio.
Ecuación del modelo observacional. Vamos a considerar un modelo para los datos de la forma
Donde:
: Observación en el tiempo .
: Estado del modelo dinámico.
: Ruido observacional.
Características del ruido observacional . Ejemplos comununes incluyen:
Caso estándar: Se asume que los ruidos son independientes e idénticamente distribuidos (i.i.d.) de forma Gaussiana , con valor medio nulo y varianza constante para cada sitio muestreado. Se supone que este ruido no depende del valor de , aunque no siempre es cierto.
Ruido correlacionado: Común en series de tiempo, donde la correlación entre dos errores es distinta de cero: para .
Nota estadística: Si dos distribuciones son Gaussianas y tienen correlación 0, son independientes. Si no son Gaussianas, tener correlación 0 no implica independencia.
Ajuste de Trayectorias
El problema central es: dadas las observaciones e , ¿cómo estimamos los parámetros que mejor describen la dinámica subyacente? El objetivo es convertir esto en un problema de optimización, buscando minimizar una función de costo que compare las observaciones reales con las trayectorias generadas por el modelo . Esto se va a realizar mediante el método de cuadrádos mínimos no lineales, el cual en el contexto de este curso llamaremos ajuste de trayectorias (trajectory matching) Ramsay & Hooker (2017):
Ajuste de Trayectorias: A diferencia del fiteo lineal de una recta, acá se compara con una función que depende de de manera no trivial.
Más adelante veremos que minimizar el cuadrado de los errores asume inherentemente un ruido de naturaleza Gaussiana.
Ejemplo (continuado)¶
Inferencia en el sistema Lotka-Volterra: Si salimos al campo y medimos las poblaciones de presas () y depredadores () a lo largo del tiempo, nuestra función de costo (o pérdida) a minimizar será:
Un optimizador resolverá numéricamente las ODEs de Lotka-Volterra en cada iteración, ajustando sistemáticamente el vector hasta que la trayectoria predicha pase lo más cerca posible de nuestros datos ruidosos.
Ecuaciones diferenciales ordinarias neuronales (NODEs)¶
Las Neural Ordinary Differential Equations (NODEs), introducidas formalmente por Chen et al. (2018), representan un cambio de paradigma al fusionar el aprendizaje profundo con los sistemas dinámicos continuos.
1. Generalización de Modelos Clásicos¶
Una forma intuitiva de entender las NODEs es viéndolas como una generalización de modelos dinámicos preexistentes. Por ejemplo, en el modelo de Lotka-Volterra, podemos reemplazar o aumentar los términos de interacción utilizando redes neuronales:
En este caso, los parámetros internos de y (pesos y sesgos) pasan a formar parte del vector global de parámetros a estimar, , potencialmente junto con y .
2. Definición Formal¶
Si generalizamos por completo (sin suponer ningún término de crecimiento o muerte específico predefinido), obtenemos una NODE. En su forma más abstracta, una NODE parametriza la derivada del estado continuo de un sistema directamente a través de una red neuronal:
Donde representa el estado del sistema en un tiempo dado, y engloba todos los parámetros entrenables de la red neuronal.
3. Propiedades y Consideraciones Clave¶
Aproximación universal: Al estar basadas en redes neuronales, las NODEs heredan la capacidad de ser aproximadores universales Goodfellow et al. (2016). Tienen la flexibilidad necesaria para aprender y representar una gama casi ilimitada de dinámicas continuas a partir de datos empíricos.
Intratabilidad numérica: Advertencia: Al llevar el modelo a este nivel de complejidad no lineal, un problema frecuente en la optimización es caer en regiones del espacio de parámetros donde el sistema se vuelve matemáticamente inestable o demasiado costoso de resolver para los solvers de las ecuaciones diferenciales.
Implementación Computacional en Julia¶
A continuación, implementamos el modelo Lotka-Volterra en Julia.
Nosotros vamos a contar brevemente los componentes principales de la resolución numérica.
En Julia, usamos ! en el nombre de la función para indicar que modifica sus argumentos in-place (es decir, no tenemos un return)
Usamos DifferentialEquations.jl para definir y resolver la ODE, y Plots.jl para visualizar la solución.
using DifferentialEquations
using Plots
using Statistics
using RandomIntroducimos la definición del sistema dinámico de Ecuaciones Diferenciales Ordinarias. La siguiente función implementa el lado derecho del sistema de Lotka-Volterra. Dado el estado actual u=(x,y), el tiempo t y el vector de parámetros p, calcula la derivada du/dt.
function lotka_volterra!(du, u, p, t)
x, y = u # x = presas, y = depredadores (esto es lo mismo que hacer u[1], u[2])
α, γ, β, η = p # Desempaquetamos el vector p
du[1] = α * x - γ * x * y
du[2] = -β * y + η * x * y
endNotar que esta función no resuelve todavía la ecuación: sólo define el campo vectorial del sistema.
Ahora fijamos un conjunto de parámetros, el estado inicial y el intervalo temporal en el que queremos resolver la dinámica.
α = 1.0 # Nacimiento de presas
β = 0.1 # Tasa de depredación
δ = 0.075 # Reproducción del depredador
γ = 1.5 # Muerte del depredador
p_true = [α, β, δ, γ]
# (condiciones iniciales y horizonte temporal)
u0 = [10.0, 5.0]
tspan = (0.0, 30.0)ODEProblem es una función de Julia para resolver una ecuación diferencial ordinaria, por eso le mandamos la función, la condición inicial y un tiempo para resolver.
prob = ODEProblem(lotka_volterra!, u0, tspan, p_true)Acá resolvemos el problema, elegimos con qué solver (en nuestro caso Tsit5 -método Runge-Kutta explícito de orden 5 con estimador de orden 4-) y cada cuánto se va a guardar, nivel de tolerancia, nivel de error. Se define la parte numérica.
sol = solve(prob, Tsit5(), saveat=0.1)El argumento saveat=0.1 indica cada cuánto queremos guardar la solución para inspeccionarla o graficarla. No necesariamente coincide con el paso interno que usa el solver para integrar la ecuación.
En sol está la solución al problema
print(sol)Este ejemplo computacional resume la lógica general de la clase: partimos de una dinámica continua escrita como ODE, la resolvemos numéricamente a partir de una condición inicial y obtenemos trayectorias que luego pueden compararse con datos observados. En un problema de inferencia, este cálculo hacia adelante se repite muchas veces dentro de un algoritmo de optimización para estimar . En una NODE, la diferencia es que parte o todo el campo vectorial deja de fijarse manualmente y pasa a ser aprendido a partir de los datos.
- Ascher, U. M. (2008). Numerical methods for evolutionary differential equations. SIAM.
- Ramsay, J., & Hooker, G. (2017). Dynamic data analysis. Springer New York, New York, NY. Doi, 10, 978–1.
- Chen, R. T., Rubanova, Y., Bettencourt, J., & Duvenaud, D. K. (2018). Neural ordinary differential equations. Advances in Neural Information Processing Systems, 31.
- Goodfellow, I., Bengio, Y., Courville, A., & Bengio, Y. (2016). Deep learning (Vol. 1). MIT press Cambridge.
- Rackauckas, C., & Nie, Q. (2016). DifferentialEquations.jl – A Performant and Feature-Rich Ecosystem for Solving Differential Equations in Julia. Journal of Open Research Software, 5(1), 15. 10.5334/jors.151