Universal Differential Equations (UDEs)¶
Fecha: 15/04/2026
Vimos el modelo de Lotka-Volterra, que tiene cuatro parámetros representados como = (, , y ). Según los valores de estos parámetros y dada una condición inicial, el sistema genera distintas trayectorias. A estas trayectorias se les puede agregar ruido gaussiano para representar los datos que observamos en la realidad.
A continuación tenemos dos implementaciones interactivas del modelo de Lotka-Volterra, una en Python y otra en Julia. En ambos casos se pueden modificar los parámetros y explorar cómo cambian las trayectorias temporales y el retrato de fases.
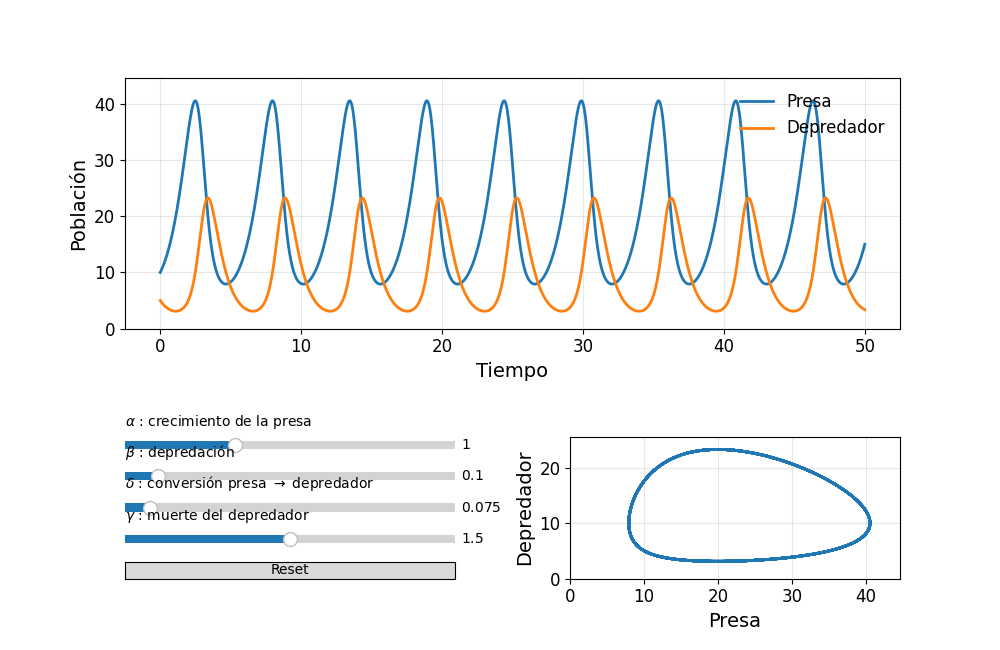
Interfaz interactiva en Python para explorar la dinámica del modelo de Lotka-Volterra variando sus parámetros.
Acá hacemos una distinción importante:
El estado del sistema es la solución de las ecuaciones diferenciales.
En la mayoría de los casos, este estado es desconocido.
En la realidad observamos solo algunos puntos del sistema y no conocemos la dinámica subyacente.
Además, las observaciones suelen tener ruido.
En muchos casos, el modelo observacional se construye a partir del modelo del estado. Por lo tanto, el modelo observacional dependerá tanto de la dinámica del sistema como del ruido de medición.
Hasta ahora, podemos resumir la situación de la siguiente manera:
donde representa los parámetros del sistema, el estado y el ruido observacional.
En este tipo de modelos, la evolución del estado no depende del ruido. El ruido aparece únicamente en las observaciones. En general, la intensidad del ruido no se conoce y puede terminar siendo otro parámetro a estimar.
Una estrategia para ajustar el sistema a los datos consiste en minimizar el cuadrado de los residuos entre las observaciones y la trayectoria predicha por el modelo. Este procedimiento se conoce como ajuste por trayectorias o cuadrados mínimos no lineales. Para una discusión más detallada de esta metodología, ver la Clase N.º 2.
En el caso de Lotka-Volterra tenemos cuatro parámetros. Al graficar el valor de la función de pérdida en un mapa 2D, eligiendo alguna combinación de dos parámetros, ya se pueden observar problemas como la presencia de mínimos locales.
NODEs¶
La idea de las redes neuronales para ecuaciones diferenciales ordinarias, o Neural ODEs, es reemplazar la función que describe la dinámica del sistema por una red neuronal:
¿Por qué hacer esto?
Porque las redes neuronales son aproximadores universales. Entonces, dados ciertos datos observacionales, la red puede aproximar el comportamiento del sistema incluso sin conocer explícitamente la ecuación que rige el fenómeno.
Una red neuronal está compuesta, en general, por tres partes: una capa de entrada, una o más capas ocultas y una capa de salida. Cada capa tiene una cierta cantidad de neuronas, que depende del problema que se quiera resolver.
Matemáticamente, una red neuronal feedforward puede escribirse como una composición de transformaciones afines y funciones de activación no lineales. Si la entrada es , una red con capas puede representarse como
donde cada capa tiene la forma
Aquí, y son los pesos y sesgos de la capa , respectivamente. Las funciones introducen la no linealidad en cada capa. El conjunto de parámetros de la red es entonces
Algunas de las funciones de activación más comunes son
y
En nuestro caso, la red recibe como entrada el vector de estado y devuelve una aproximación de la función dinámica .
Volviendo al ejemplo de Lotka-Volterra, supongamos que conocemos una parte de la dinámica. Sabemos que, en ausencia de interacción, la población de conejos crece y la de lobos decrece. Sin embargo, no sabemos exactamente cómo interactúan ambas poblaciones.
En ese caso, en lugar de reemplazar toda la dinámica por una red neuronal, podemos conservar la parte conocida del modelo y reemplazar solo la parte desconocida:
En este caso, los parámetros a ajustar son tanto los parámetros conocidos del modelo como los parámetros de las redes neuronales:
Calibración con respecto a la condición inicial¶
Hasta ahora planteamos el ajuste del modelo como un problema de optimización en los parámetros . Sin embargo, la condición inicial también puede ser incierta y, por lo tanto, pensarse como otra variable a estimar.
Esto es relevante porque, aun cuando fijamos la forma del modelo, la función de pérdida puede presentar mínimos locales. Por eso, una mala elección de puede dificultar el ajuste y alejarnos de la mejor solución posible.
En ese caso, el problema consiste en minimizar la función de pérdida no solo con respecto a , sino también con respecto a . Es decir, en lugar de buscar únicamente los parámetros del modelo, buscamos conjuntamente los parámetros y la condición inicial que mejor reproducen las observaciones.
Esto es especialmente útil cuando no conocemos con precisión el estado inicial del sistema. En muchos casos, elegir una buena condición inicial sigue siendo un problema más simple que determinar directamente todos los parámetros del modelo.