Physics-Informed Neural Networks (PINNs)¶
Fecha: 11/05/2026
Tres tipos de algoritmos para incorporar ecuaciones diferenciales¶
Cuando queremos estimar o aproximar una ecuación diferencial con modelos de aprendizaje automático, hay tres enfoques principales:
Emuladores: se estima la ecuación diferencial con otro modelo de ML. Por ejemplo, cuando hay ecuaciones costosas (Navier-Stokes, etc.)
Restricciones suaves (vía Lagrangiano): el modelo se entrena minimizando una función de costo empírica más un término de penalización que incentiva satisfacer la ecuación diferencial. Por ejemplo, las PINNs:
Restricciones fuertes (se satisfacen estrictamente): el modelo debe satisfacer la ecuación diferencial en todo momento. Son las NODE y UDE:
Dualidad Lagrangiana¶
Un resultado fundamental de la optimización con restricciones establece que, si relajamos la restricción fuerte por una restricción aproximada , existe un tal que la solución del problema con restricción suave (penalizado con ) coincide con la solución del problema con restricción fuerte relajada Boyd & Vandenberghe (2004):
Dificultades al entrenar PINNs¶
En la práctica, entrenar PINNs tiene problemas importantes de optimización. La función de pérdida puede tener múltiples términos: (ajuste a los datos) y uno o mas términos de penalización , uno por cada restricción (condición inicial, condición de borde, residuo de la ecuación diferencial, etc.).
Cuando es muy grande, el problema se vuelve mal condicionado: los gradientes del término de penalización dominan, entonces el optimizador tiene problemas para elegir la dirección óptima.
![Curvas de nivel de \mathcal{L}_{\text{PINN}} (rosa) alrededor de la variedad donde D[x(\cdot,\theta)]=0 (negro). En un entorno de D[x(\cdot,\theta)]=0 es probable que la PINN esté mal condicionada.](/DM2026-Curso/build/no9_pinns_mal_condic-437dbf4aedf6cf9e3c4c1af68ad7b288.png)
Curvas de nivel de (rosa) alrededor de la variedad donde (negro). En un entorno de es probable que la PINN esté mal condicionada.
Selección de ¶
En general, el vector de hiperparámetros controla cuánto pesa cada restricción. Hay tres estrategias para elegirlos:
Adimensionalización: normalizar todos los términos para que operen en la misma escala:
Elección democrática — valor absoluto: elegir los tal que las magnitudes de todos los términos sean iguales en cada iteración:
Elección democrática — norma de gradientes: igualar las normas de los gradientes de cada término, de forma que ninguno domine la actualización:
Implementación¶
Problema directo¶
Vemos una implementación de PINN directo.
t0, T = tspan
scale_layer_inp = WrappedFunction(t -> (t .- t0) ./ (T - t0))
scale_layer_out = WrappedFunction(x -> 10.0 .* x)Definimos la red neuronal:
nn = Chain(
scale_layer_inp,
Dense(1 => 5, tanh),
Dense(5 => 10, tanh),
Dense(10 => 10, tanh),
Dense(10 => 2),
scale_layer_out
)Puntos de colocación: En una PINN hay que elegir puntos en el dominio temporal donde evaluar el residuo de la ecuación diferencial .
N_col = 100
# t_col = collect(range(tspan[1], tspan[2], length=N_col))
# t_col = 10.0.^collect(range(log10(tspan[1] + 1e-10), log10(tspan[2]), length = N_col))
t_col = [
10.0.^collect(range(log10(tspan[1] + 1e-10),
log10(tspan[2]), length = div(N_col, 2)));
collect(range(tspan[1], tspan[2], length=div(N_col, 2)))
]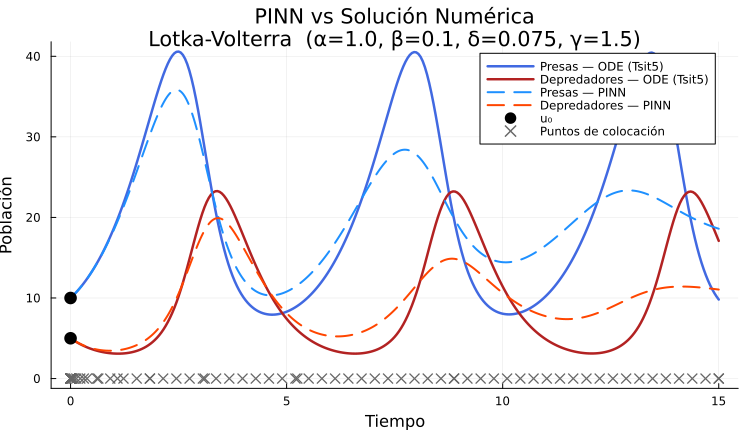
Las cruces son los puntos de colocación: donde la ecuación diferencial se está evaluando.
Este es un ejemplo que claramente no convergió bien, probablemente el resultado mejoraría ejecutando el código por mas tiempo, pero.. ¿Qué mas podemos hacer?
Técnicas para mejorar la convergencia¶
Puntos de colocación: La ubicación de los puntos de colocación no es arbitraria. En este ejemplo, exploramos solo dos opciones:
Uniforme: puntos distribuidos uniformemente en el dominio.
Escala logarítmica desde : mayor densidad de puntos cerca de la condición inicial. Una solución espuria que la red puede encontrar es arrancar en e irse inmediatamente a la trayectoria nula, lo que satisface trivialmente las ecuaciones de Lotka-Volterra. Concentrar puntos al principio fuerza al modelo a seguir la trayectoria correcta desde .
Forzar la condición inicial exactamente: Vemos cómo implementamos la función de costo:
function pinn_loss_components(ps)
u_ic = nn([tspan[1]], ps, st)[1]
ic_loss = sum((u_ic .- u0) .^ 2)
phys_residuals = map(t_col) do t_i
u = nn([t_i], ps, st)[1]
dudt = nn_dudt(t_i, ps, st)
rhs = lv_rhs(u)
sum((dudt .- rhs) .^ 2)
end
phys_loss_weighted = λ_physics * mean(phys_residuals)
return ic_loss, phys_loss_weighted
end
pinn_loss(ps) = sum(pinn_loss_components(ps))Estamos definiendo a la condición inicial como una restricción suave. No es ideal. ¿Cómo podemos imponerla como restricción fuerte? Una reparametrización directa es:
En se tiene independientemente de los parámetros. Sin embargo, el factor crece linealmente, obligando a la red a desaprender un trend lineal.
Una mejor alternativa es usar una función acotada:
donde . Por ejemplo, con cualquier número finito satisface y cuando .
Podemos aplicar esto al ejemplo:
function u_ansatz(t_val, ps, st)
raw = nn([t_val], ps, st)[1] # NN(t) ∈ ℝ²
return u0 .+ t_val .* raw # u₀ + t·NN(t)
end
# Derivada temporal del ansatz por diferencias finitas centrales
function u_ansatz_dudt(t_val, ps, st; h=1e-4)
u_fwd = u_ansatz(t_val + h, ps, st)
u_bwd = u_ansatz(t_val - h, ps, st)
return (u_fwd .- u_bwd) ./ (2h)
end
function pinn_loss(ps)
phys_residuals = map(t_col) do t_i
u = u_ansatz(t_i, ps, st)
dudt = u_ansatz_dudt(t_i, ps, st)
rhs = lv_rhs(u)
sum((dudt .- rhs) .^ 2)
end
return mean(phys_residuals)
end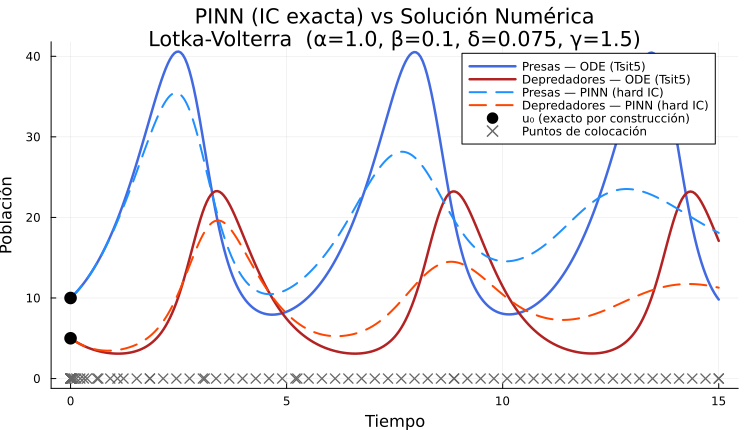
Mejora... pero no es ideal.
Aún podría ser mejorable este resultado. Pero no es lo que nos interesa, no buscamos que una PINN sea excelente resolviendo una ecuación diferencial. Donde verdaderamente brillan las PINN es en el problema inverso.
Problema inverso¶
En el problema inverso no solo se conoce la condición inicial sino también observaciones de la trayectoria. El objetivo deja de ser únicamente ajustar y pasa a ser ajustar la trayectoria completa. En este caso se aplica a Lotka-Volterra sin conocer los parámetros del sistema.
Generación de datos observados¶
Se resuelve la ODE con los parámetros verdaderos (desconocidos para la PINN) y se submuestran puntos uniformes:
const α_true = 1.0; const β_true = 0.1
const δ_true = 0.075; const γ_true = 1.5
const u0 = [10.0, 5.0]
const tspan = (0.0, 15.0)
prob_true = ODEProblem(lotka_volterra!, u0, tspan, [α_true, β_true, δ_true, γ_true])
sol_true = solve(prob_true, Tsit5(), saveat=0.01)
M_obs = 40
t_obs = collect(range(tspan[1], tspan[2], length=M_obs))
u_obs = hcat([sol_true(t) for t in t_obs]...) # (2, M_obs)Parámetros entrenables¶
Los parámetros de la ODE se inicializan lejos de los valores verdaderos y se agrupan junto con los pesos de la red en un único NamedTuple que Optimisers.jl puede diferenciar recursivamente:
p_ode_init = [0.5, 0.05, 0.04, 1.0] # [α̂, β̂, δ̂, γ̂]
theta = (nn = nn_ps, ode = copy(p_ode_init))Función de pérdida¶
const λ_phys = 1.0
function inverse_loss_components(theta)
nn_ps = theta.nn
α̂, β̂, δ̂, γ̂ = theta.ode
data_residuals = map(1:M_obs) do j
u_pred = nn([t_obs[j]], nn_ps, st)[1]
sum((u_pred .- u_obs[:, j]) .^ 2)
end
data_loss = mean(data_residuals)
phys_residuals = map(t_col) do t_i
u = nn([t_i], nn_ps, st)[1]
dudt = nn_dudt(t_i, nn_ps, st)
x, y = u[1], u[2]
rhs = [α̂*x - β̂*x*y,
δ̂*x*y - γ̂*y]
sum((dudt .- rhs) .^ 2)
end
phys_loss = λ_phys * mean(phys_residuals)
return data_loss, phys_loss
end
inverse_loss(theta) = sum(inverse_loss_components(theta))Resultados¶
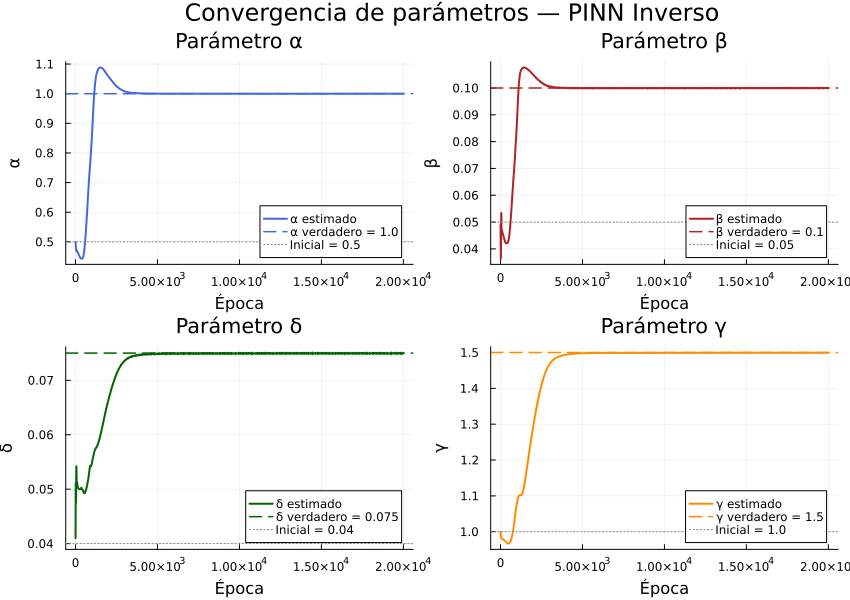
Convergencia de los parámetros estimados hacia los valores verdaderos a lo largo del entrenamiento.
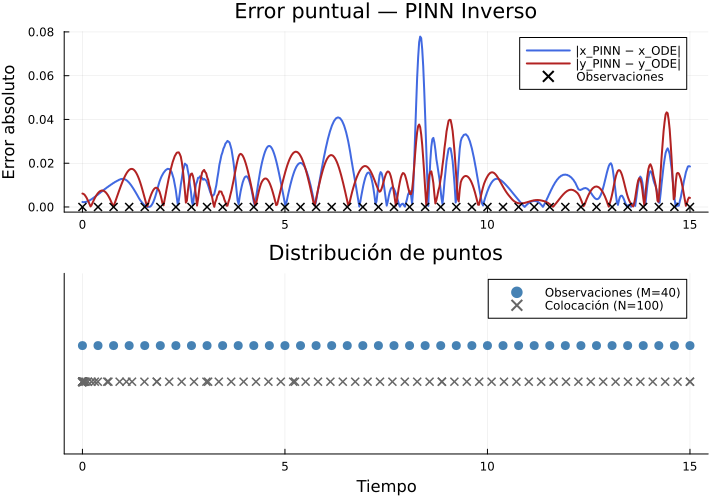
El error puntual muestra que la PINN ajusta exactamente en los puntos de colocación y en los puntos de observación, pero el error crece en las regiones intermedias.
- Boyd, S., & Vandenberghe, L. (2004). Convex optimization. Cambridge university press.
- Lu, L., Pestourie, R., Yao, W., Wang, Z., Verdugo, F., & Johnson, S. G. (2021). Physics-Informed Neural Networks with Hard Constraints for Inverse Design. SIAM Journal on Scientific Computing, 43(6), B1105–B1132. 10.1137/21m1397908