Fecha: 22/04/2026
Estas notas introducen el problema general de optimización que aparece al ajustar modelos dinámicos a datos. En particular, veremos cómo se define una función de costo, qué significa buscar parámetros óptimos, qué diferencias hay entre búsqueda global y búsqueda local, y cómo se conectan los métodos de optimización con el ajuste de trayectorias de ODEs.
Problema general de optimización¶
En muchos problemas de modelado queremos encontrar parámetros que hagan que un modelo describa lo mejor posible los datos observados. Para eso definimos una función de costo o función de pérdida , que mide qué tan mal se ajusta el modelo para un cierto valor de los parámetros.
De manera general, buscamos resolver el problema
donde:
es el vector de parámetros del modelo,
es la cantidad de parámetros,
es el espacio de búsqueda o conjunto de valores admisibles para ,
e representan los datos disponibles, y
mide el desacuerdo entre el modelo y los datos.
El objetivo es encontrar un parámetro que minimice la función de costo:
En la práctica, incluso si escribimos el problema como una minimización exacta, no siempre podemos encontrar el mínimo global de forma analítica. Por eso necesitamos algoritmos numéricos de optimización.
¿De dónde sale la función de costo?¶
Una pregunta central es cómo construir la función . En general, la función de costo se elige para cuantificar el error entre las observaciones y las predicciones del modelo.
Por ejemplo, si tenemos observaciones y un modelo que predice valores , una elección clásica es la suma de errores cuadráticos:
Esta elección penaliza más fuertemente errores grandes y conduce al método de cuadrados mínimos. En clases anteriores apareció en el contexto de ajuste de trayectorias: se comparan datos observados contra trayectorias generadas por una ODE.
Tipos de algoritmos de optimización¶
Podemos clasificar los algoritmos de optimización según la información que usan de la función de costo y según la región del espacio de parámetros que exploran.
Una primera distinción importante es entre:
Búsqueda global: intenta explorar ampliamente el espacio para encontrar el mejor mínimo posible.
Búsqueda local: parte de un valor inicial y mejora iterativamente la solución en una vecindad.
Búsqueda global¶
La búsqueda global intenta encontrar el mínimo global de en todo el espacio de parámetros .
Una estrategia simple consiste en evaluar la función de costo en muchos puntos del espacio de parámetros, por ejemplo mediante una grilla.
La búsqueda global puede ser útil cuando el espacio de parámetros es pequeño, cuando la función tiene muchos mínimos locales o cuando no tenemos una buena inicialización. Sin embargo, suele ser costosa. En dimensión baja ( 4) esto puede ser razonable, pero en dimensión alta se vuelve rápidamente inviable.
Búsqueda local¶
La búsqueda local comienza desde un punto inicial y genera una sucesión de parámetros
tal que
buscando que la función de costo disminuya (en promedio) en cada paso.
A diferencia de la búsqueda global, estos métodos no garantizan necesariamente encontrar el mínimo global. Pueden converger a un mínimo local, a un punto silla, o incluso fallar si la función está mal condicionada o si la inicialización es mala.
Métodos de búsqueda local¶
Dentro de los métodos locales, podemos distinguir tres grandes familias:
Métodos de orden cero: sólo evalúan .
Métodos de primer orden: usan y su gradiente .
Métodos de segundo orden: usan , el gradiente y la información de curvatura, usualmente mediante la matriz Hessiana.
Métodos de orden cero¶
Los métodos de orden cero no usan derivadas. Sólo necesitan evaluar la función de costo en distintos valores de .
Esto puede ser útil cuando:
La función no es diferenciable.
Calcular derivadas es demasiado costoso.
El modelo funciona como una caja negra.
Sin embargo, al no usar información geométrica de la función, suelen necesitar muchas evaluaciones de .
No los usaremos en este curso, pero dejamos algunos ejemplos de métodos de orden cero.
Nelder-Mead (Método del Símplex)¶
Uno de los métodos sin derivadas más populares. Opera sobre un símplex geométrico de puntos en , aplicando operaciones de reflexión, expansión, contracción y reducción para moverse hacia el mínimo. Es eficaz en dimensiones bajas, pero tiene dificultades en altas dimensiones debido a la pérdida de efectividad de los pasos de expansión y contracción.
Búsqueda Directa (Direct Search o Pattern Search)¶
Los métodos de búsqueda directa evalúan la función objetivo en un conjunto de puntos candidatos (“poll points”) y seleccionan el siguiente iterado como aquel que produce un decremento suficiente; si ningún punto lo logra, se reduce el tamaño del paso.
Métodos de primer orden¶
Los métodos de primer orden usan el gradiente de la función de costo:
El gradiente indica la dirección de mayor crecimiento local de la función. Por eso, para minimizar, nos movemos en la dirección opuesta al gradiente.
Descenso por gradiente¶
El método más básico de primer orden es el descenso por gradiente. La actualización es
donde es el tamaño de paso o learning rate en la iteración .
La intuición es simple: si el gradiente apunta hacia donde aumenta más rápido, entonces apunta hacia donde disminuye más rápido localmente.
Gradiente con momento (o Momentum)¶
Una mejora común del descenso por gradiente es agregar momento. La idea es que la dirección de actualización no dependa solamente del gradiente actual, sino también de las direcciones tomadas en pasos anteriores.
Una forma de escribirlo es:
con
para .
El término actúa como una media móvil de gradientes. Esto puede suavizar oscilaciones y acelerar el avance en direcciones consistentes.
Forma general de los métodos de primer orden¶
Una forma más general de escribir estos algoritmos es
con
Es decir, la dirección de actualización puede depender del gradiente actual, de gradientes anteriores y de parámetros anteriores.
Para más detalles sobre métodos de optimización, léase Ruder (2016).
Método Adam (Adaptive Moment Estimation)¶
El optimizador Adam combina ideas de momento con estimaciones adaptativas de escala para cada coordenada del gradiente. Por ser muy robusto ante elección del learning rate inicial, es muy usado en entrenamiento de redes neuronales.
Momento: acumula una media móvil del gradiente.
Adaptación del paso: acumula una media móvil del gradiente al cuadrado, para escalar el learning rate por parámetro:
La actualización queda:
donde y
Métodos de segundo orden¶
Los métodos de segundo orden usan información sobre la curvatura de la función de costo. Esta información está contenida en la matriz Hessiana:
Mientras que el gradiente indica una dirección de descenso local, el Hessiano describe cómo cambia ese gradiente alrededor del punto actual.
Método de Newton¶
El método de Newton usa una aproximación cuadrática local de la función de costo. Su actualización puede escribirse como
La diferencia principal con descenso por gradiente es que la dirección de descenso se corrige usando la curvatura local de la función.
Métodos cuasi-Newton¶
Los métodos cuasi-Newton buscan aproximar la información de segundo orden sin calcular explícitamente el Hessiano exacto. Por este motivo se conocen también como “métodos de orden 1.5”.
En lugar de usar directamente, construyen una aproximación a la curvatura de la función de corso a partir de gradientes y pasos anteriores, lo que permite capturar parte de la ventaja de Newton sin pagar el costo completo de calcular el Hessiano exacto.
BFGS¶
El método cuasi-Newton más popular es el de Broyden, Fletcher, Goldfarb, Shanno, conocido como “BFGS”.
La actualización de la aproximación inversa del Hessiano es:
donde:
(paso en los parámetros),
(cambio en el gradiente), y
La clave es que se actualiza con información del gradiente en dos puntos consecutivos, satisfaciendo la condición secante:
que es la versión discreta de lo que haría el Hessiano verdadero.
Optimización en ajuste de trayectorias de ODEs¶
Volvamos ahora al caso que aparece en el curso: queremos ajustar parámetros de una ODE a partir de datos observados.
Supongamos que tenemos un sistema dinámico
Para cada valor de , resolver la ODE produce una trayectoria . Si observamos datos en tiempos , una función de pérdida natural es
Como se obtiene resolviendo numéricamente una ODE, también podemos escribir esta pérdida como
Desde el punto de vista de la optimización, el problema sigue siendo
pero la dependencia de respecto de está mediada por la solución de una ecuación diferencial.
Gradiente de la pérdida en ODEs¶
Para usar métodos de primer orden necesitamos calcular .
Si
entonces, aplicando regla de la cadena, obtenemos una expresión del tipo
El término clave es
que se conoce como sensibilidad de la solución respecto de los parámetros.
Si y , entonces
Cada columna de representa cómo cambia el estado del sistema cuando se modifica uno de los parámetros.
En la practica NO es necesario calcular esta matriz S, ya que calcular esa matriz es muy costoso.
Cierre de la clase¶
La optimización es el puente entre el modelo dinámico y los datos. En el contexto de ODEs, cada valor de los parámetros define una trayectoria; la función de costo mide qué tan lejos está esa trayectoria de las observaciones; y el algoritmo de optimización actualiza los parámetros para reducir ese desacuerdo.
En resumen:
Definimos una función de costo .
Buscamos un parámetro óptimo que minimice esa función.
Podemos usar búsqueda global o búsqueda local.
Los métodos locales pueden usar sólo evaluaciones de , gradientes o información de segundo orden.
En ODEs, evaluar la pérdida implica resolver numéricamente el sistema.
Para optimizar eficientemente, necesitamos entender cómo cambia la solución de la ODE respecto de los parámetros.
Implementación computacional en Julia: optimización de una UDE¶
A continuación presentamos un ejemplo computacional cuyo objetivo principal es mostrar cómo aparece la optimización cuando ajustamos una dinámica parcialmente desconocida.
El código completo de este ejemplo se encuentra disponible en 05_LV_inverse_UDE.
Para una explicación previa del modelo Lotka-Volterra y del problema dinámico que se busca resolver, se puede consultar la Clase_2.
En este ejemplo, partimos de datos generados por un sistema Lotka-Volterra conocido y entrenamos una Universal Differential Equation (UDE) para reproducir esa trayectoria. La parte central del problema es estimar los parámetros de una red neuronal que aparece dentro de la ecuación diferencial.
Desde el punto de vista de la optimización, queremos resolver un problema de la forma
donde representa los pesos y sesgos de la red neuronal, y mide qué tan lejos está la trayectoria predicha por el modelo de la trayectoria observada.
¿Qué se está optimizando?¶
En una ODE clásica, los parámetros suelen ser coeficientes explícitos del modelo. Por ejemplo, en Lotka-Volterra podríamos querer estimar parámetros como , , o .
En este ejemplo, en cambio, parte de la dinámica se reemplaza por una red neuronal. La UDE tiene la forma general:
donde:
es el estado del sistema.
representa la parte de la dinámica que dejamos fija.
es la parte aprendida por la red neuronal.
son los parámetros entrenables.
En el código, la dinámica aprendible se define como:
function lotka_volterra_ude!(du, u, p, t, p_true)
x, y = u
interaction, _ = nn([x, y], p, nn_st)
du[1] = p_true[1] * x + interaction[1]
du[2] = -p_true[4] * y + interaction[2]
endLa red neuronal recibe el estado actual y devuelve dos términos de interacción. Por lo tanto, los parámetros que se optimizan no son directamente los coeficientes clásicos del sistema, sino los pesos internos de la red que modela la parte faltante de la dinámica.
Predicción: evaluar un punto del espacio de parámetros¶
Para evaluar la función de costo en un punto , el código debe resolver la UDE con esos parámetros. Esto aparece en la función predict:
function predict(ps)
_prob = remake(prob_ude, u0=u0, tspan=tspan, p=ps)
Array(solve(_prob, Vern7(), saveat=t_obs,
abstol=1e-6, reltol=1e-6,
sensealg=QuadratureAdjoint(autojacvec=ReverseDiffVJP(true))))
endConceptualmente, esta función realiza el siguiente procedimiento:
Es decir, predict(ps) no hace una predicción directa como en una regresión lineal simple. Primero construye un problema de ODE usando los parámetros actuales de la red neuronal y luego lo resuelve numéricamente.
Esto hace que el problema de optimización sea más costoso: cada evaluación de la pérdida requiere integrar la dinámica.
La función remake permite reutilizar la estructura del problema prob_ude, pero reemplazando los parámetros actuales por ps. Esto es útil porque durante el entrenamiento los parámetros cambian en cada iteración.
Función de costo¶
La función de costo está definida en el código como:
function loss(ps)
ŷ = predict(ps)
size(ŷ, 2) != length(t_obs) && return Inf
return mean((ŷ .- target) .^ 2)
endEsta función toma los parámetros actuales ps, resuelve la UDE y compara la trayectoria predicha con los datos de referencia target.
Matemáticamente, implementa un error cuadrático medio:
Donde:
es el estado predicho por la UDE en el tiempo .
es el dato observado o de referencia.
son los parámetros de la red neuronal.
Entonces el problema completo es:
Esta es la conexión principal con la clase: la función de costo mide el desacuerdo entre modelo y datos, y el optimizador busca parámetros que reduzcan ese desacuerdo.
Entrenamiento en dos fases¶
El código entrena el modelo en dos etapas:
adam_iters = 1500
bfgs_iters = 1000Primero usa Adam y luego BFGS. La idea no es cambiar la función de costo, sino cambiar el método que se usa para minimizarla.
El esquema general es:
Ambas fases minimizan la misma pérdida:
Lo que cambia es la estrategia de actualización de los parámetros.
Primera fase: Adam¶
La primera fase se define como:
optf = OptimizationFunction((ps, _) -> loss(ps), AutoZygote())
optprob1 = OptimizationProblem(optf, nn_ps)
res1 = Optimization.solve(optprob1, OptimizationOptimisers.Adam(),
callback = (ps, l) -> begin
push!(loss_history, l)
length(loss_history) % 50 == 0 &&
println(" [Adam] iter $(length(loss_history)) — Loss: $(round(l, digits=6))")
false
end,
maxiters = adam_iters)Adam es un método local de primer orden. Esto significa que usa información del gradiente de la función de costo, pero no usa explícitamente el Hessiano.
En términos generales, Adam actualiza los parámetros usando una dirección basada en gradientes recientes y una escala adaptativa para cada coordenada. Por eso suele ser robusto en problemas con redes neuronales, donde la función de costo puede ser irregular, no convexa y de alta dimensión.
Segunda fase: BFGS¶
Una vez terminada la etapa con Adam, el código usa la solución obtenida como punto inicial para BFGS:
optprob2 = OptimizationProblem(optf, res1.u)
res2 = Optimization.solve(optprob2,
OptimizationOptimJL.BFGS(linesearch=BackTracking()),
callback = (ps, l) -> begin
push!(loss_history, l)
n = length(loss_history) - adam_iters
n % 10 == 0 &&
println(" [BFGS] iter $n — Loss: $(round(l, digits=6))")
false
end,
maxiters = bfgs_iters)La parte clave es:
optprob2 = OptimizationProblem(optf, res1.u)BFGS es un método quasi-Newton. En lugar de usar solamente el gradiente actual, intenta construir una aproximación de la curvatura de la función de costo a partir de la historia de pasos y gradientes.
En este ejemplo, Adam cumple el rol de acercar los parámetros a una región razonable del espacio de búsqueda. Luego BFGS refina la solución aprovechando información aproximada de curvatura.
Resultado final del entrenamiento¶
Al finalizar BFGS, el código toma los parámetros finales:
nn_ps = res2.u
println("Entrenamiento finalizado. Loss final: $(round(loss_history[end], digits=6))")Estos parámetros son la solución aproximada del problema de optimización. No se garantiza que sean el mínimo global, porque el problema es no convexo. Sin embargo, si la pérdida final es baja y las trayectorias ajustan bien, podemos interpretar que el entrenamiento encontró una solución útil.
Luego se resuelve nuevamente la UDE con los parámetros entrenados:
prob_trained = ODEProblem(nn_dynamics!, u0, tspan, nn_ps)
sol_trained = solve(prob_trained, Vern7(), saveat=0.1, abstol=1e-6, reltol=1e-6)Esto permite construir la trayectoria final aprendida por el modelo.
Interpretación de la curva de pérdida¶
La primera salida importante para analizar la optimización es la curva de pérdida:
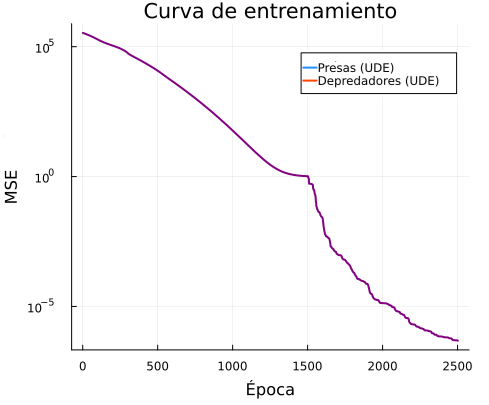
Curva de según época.
Esta curva muestra el valor de la función de costo a lo largo de las iteraciones.
Se ven dos comportamientos:
Una primera caída (hasta 1500 épocas) importante durante Adam.
Una etapa de refinamiento (luego de 1500 épocas) durante BFGS.
La curva de pérdida es el gráfico más directamente relacionado con la clase de optimización: muestra cómo el algoritmo va reduciendo la función objetivo.
Interpretación del gráfico de trayectorias¶
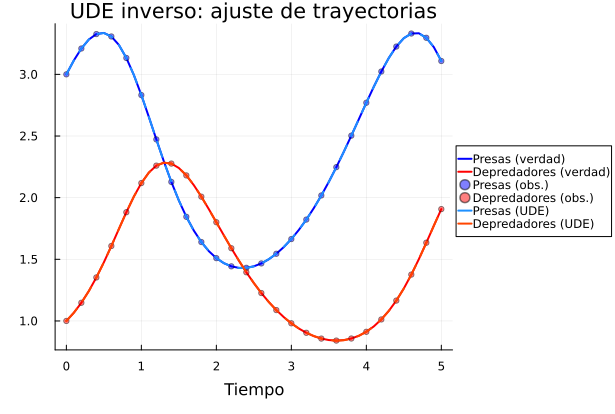
Trayectorias halladas por la NN en comparación con los datos reales.
En esta figura se comparan:
los datos de referencia,
la trayectoria producida por el modelo entrenado,
la curva de pérdida del entrenamiento.
Si la UDE entrenada se superpone bien con los puntos observados, como en el gáfico presentado, significa que los parámetros encontrados por el optimizador generan una dinámica compatible con los datos.
Interpretación de los términos de interacción aprendidos¶
El código también genera una figura para comparar las salidas de la red neuronal con los términos verdaderos de interacción:
true_f1 = @. -p_true[2] * X_traj * Y_traj
true_f2 = @. p_true[3] * X_traj * Y_traj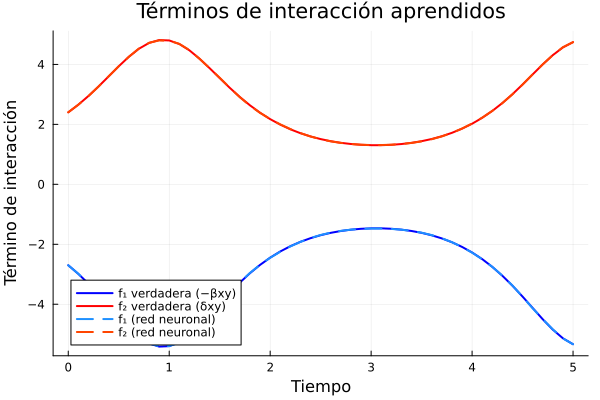
Términos de interaccion aprendidos contrastado contra los reales. Esta figura muestra solapamiento de 100%.
En este ejemplo sintético sabemos que la red debería aprender:
Este gráfico permite analizar si la optimización recuperó algo parecido a la función faltante verdadera, no sólo si logró ajustar la trayectoria.
Desde el punto de vista de optimización, este gráfico ayuda a distinguir dos niveles de éxito:
Ajuste predictivo: la trayectoria producida por el modelo se parece a los datos.
Recuperación de dinámica: la red aprendió una función interna parecida a la verdadera.
El primer objetivo puede alcanzarse sin que el segundo sea perfecto, especialmente si hay pocos datos o si sólo observamos una parte limitada del espacio de estados.
Interpretación de los heatmaps¶
La última figura que el código genera es esta:
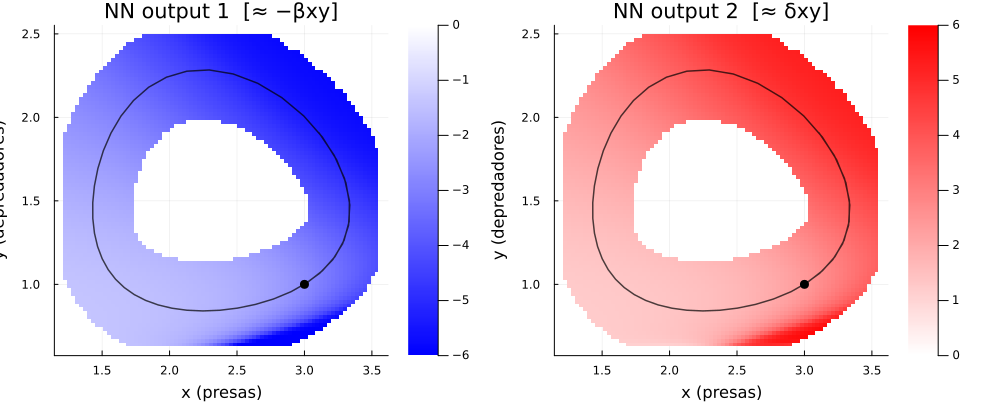
Heatmap de los valores recuperados por la NN cerca de la trayectoria. En el gradiente se puede ver la operación que la NN aprendió.
Los heatmaps muestran los valores que devuelve la red neuronal en distintas regiones del espacio de estados .
Desde el punto de vista de entrenamiento, esto permite inspeccionar cómo se comporta la función aprendida fuera de los puntos exactos usados durante la optimización.
Sin embargo, el código aplica una máscara:
sqrt(d) < mask_threshold ? nn([x, y], nn_ps, nn_st)[1][output_idx] : NaNEsto hace que sólo se grafiquen valores cerca de la trayectoria observada. La razón es importante: la red fue entrenada principalmente con información en esa región del espacio de estados. Lejos de esa región, la salida de la red puede ser una extrapolación poco confiable.
Qué nos enseña este ejemplo sobre optimización¶
Este ejemplo resume varias ideas centrales de la clase.
La función de costo no es simplemente una fórmula cerrada en los parámetros. Para evaluarla, hay que resolver una ODE.
Los gradientes se calculan a través del solver de la ODE.
Se combinan dos métodos locales:
Adam, como primera etapa robusta basada en gradientes.
BFGS, como etapa de refinamiento quasi-Newton.
Los resultados deben interpretarse en varios niveles:
disminución de la pérdida,
ajuste visual de trayectorias,
recuperación de los términos de interacción,
comportamiento de la función aprendida en el espacio de estados.
En resumen, el ejemplo muestra que ajustar una UDE no consiste solamente en resolver una ecuación diferencial, sino en resolver repetidamente muchas ecuaciones diferenciales dentro de un proceso de optimización.
- Ruder, S. (2016). An overview of gradient descent optimization algorithms. arXiv.